
The Google algorithm leak has become the hottest topic in SEO circles (and beyond) over the past few weeks. These now-public documents have allowed everyone to peek into the algorithm driving Google Search.
As a result, we can dissect the elements that determine content ranking, removing the veil of mystery from this strategic resource. If you’re trying to wrap your head around it, it’s best to revisit the story from the beginning.
So, let’s go back to the start of Google’s SEO guidelines leak.
What Exactly Happened?
What many now call the May 2024 Google leak actually started to unfold on March 13, when a person using the alias ‘yoshi-code-bot’ uploaded the leaked documents to GitHub. However, their post didn’t gain any traction until the anonymous source contacted Rand Fishkin, the co-founder of SnackToro, on May 5.
Fishkin reached out to Michael (Mike) King, the CEO of iPullRank, asking for advice. Together, they examined the matter and published their analysis on May 27. Finally, everyone started paying attention to the leak, nudging the anonymous source to reveal themselves the next day as Erfan Azimi, an SEO professional.
Azimi clarified that financial motives weren’t the reason he published the documents. Instead, this SEO practitioner wanted the truth to come out.
What’s Inside the Leaked Google Search API Documents?
The leak contains over 2,500 pages of API documentation with 14,014 features from Google’s internal ‘Content API Warehouse.’ The documents only revealed the existence of the ranking attributes without detailing their weighting or importance. These functions can modify a document’s information retrieval score or alter its ranking.
Other invaluable information, such as reasons for demotions and change history, is also inside these documents. However, we’ll discuss each of these later on.

Did Google Confirm Whether the Leaked Search Documents are Real?
Yes. Google has confirmed that the massive leak of its internal documents is authentic. However, they refused to provide any further comments.
But even before this confirmation came, Fishkin and King contacted ex-Googler friends who shared that the leaked docs had all the hallmarks of an internal Google API. These SEO professionals only published the article about the leaked Google SEO documentation after confirming these documents were legitimate and coming from inside Google’s Search division.
Another important thing to mention is that the leak was mostly likely accidental and, therefore, briefly available. However, the leaked documents contradict many of Google’s past public statements concerning which factors they use to calculate ratings. For instance, Google denied having a website authority score and explicitly rejected using Chrome data in search rankings.
Why Should You Care About the Google Search Algorithm Leak?
The Google SEO documentation leak provides remarkable insights into how this search engine ranks content, revealing key factors like re-ranking functions, the importance of link diversity and relevance (including PageRank), and user behavior metrics such as click data (including measures like badClicks and goodClicks). You should understand these details to create more effective SEO strategies that align with what Google algorithms measure and prioritize.
Now it’s time to move to the juicy part of this historical leak—the factors it includes, and what that means for the future of SEO.
What Secrets Does the Google Algorithm Leak Include?
The Google algorithm isn’t a single entity. Instead, it uses various microservices to preprocess diverse features, which are dynamically integrated to influence the SERP.
The leaked documentation indicates numerous separate ranking systems, hinting at possibly over a hundred such systems. If these aren’t exhaustive, each system could represent a unique ‘ranking signal,’ potentially adding to the 200 signals often associated with Google’s ranking methodology.
As Mike King explained in his May 27 article, we can use abstracted models of Google Search presented over the years by software engineer Jeff Dean, research engineer Marc Najork, and Google whistleblower Zach Vorhies to understand how the components of each model interact. According to their models, this API seems to be built on Google’s Spanner infrastructure, which enables limitless scalability for storing and processing data by uniting globally networked computers into a cohesive unit.
King also highlighted the ranking systems he was familiar with and clarified their function.
- Crawling: Uses the Trawler web crawling system, which includes a crawl queue and can identify each time a page changes.
- Indexing: Consists of the core indexing system (Alexandria), secondary indexing system (TerraGoogle), and SegIndexer, which allocates documents into tiers.
- Rendering: Includes the system for JavaScript called HtmlrenderWebkitHeadless.
- Processing: Consists of LinkExtractor and WebMirror. The former, as the name implies, extracts all the links from a page, while the latter handles duplication and canonicalization.
- Ranking: Its primary scoring, ranking, and serving system is named Mustang, and it includes the Ascorer algorithm, which ranks pages before re-ranking changes. The second system is called NavBoost. – It re-ranks pages based on user behavior’s click logs. FreshnessTwiddler re-ranks documents depending on their freshness, while WebChooserScorer defines the names of features appearing in snippet scoring.
- Serving: Google Web Server receives data that will be displayed to the user. Meanwhile, SuperRoot sends messages to the servers and handles the post-processing system that determines re-ranking and which results will show. The other three systems are SnippetBrain, Cookbook, and Glue, which generate snippets, signals, and universal results based on user behavior.
Obviously, the leaked documents have more systems, but their function is still a mystery.
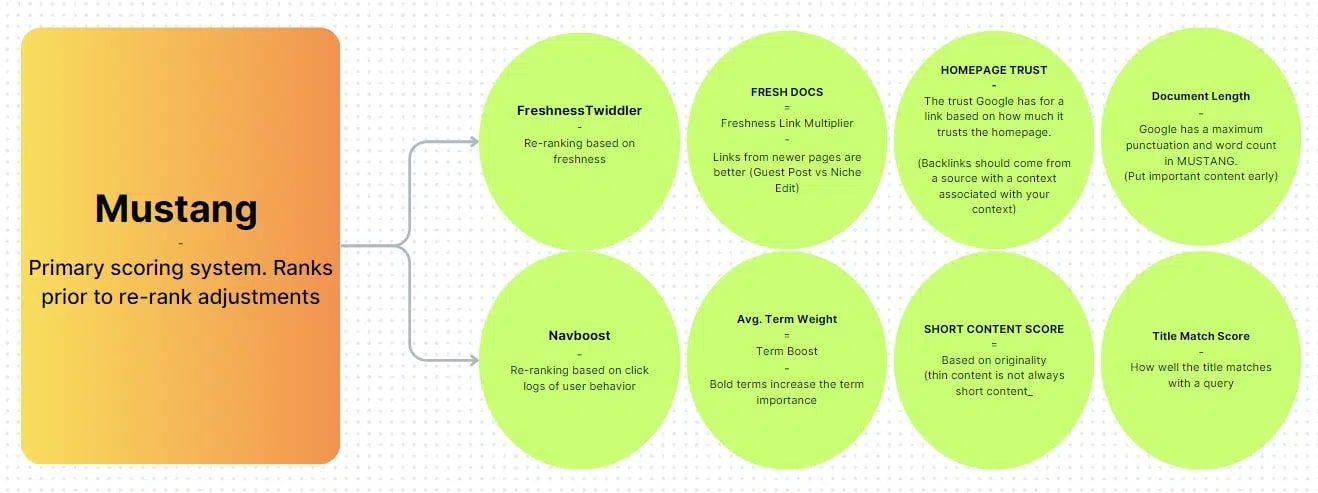
What Exactly are Twiddlers?
Twiddlers are secondary re-ranking functions that adjust the results of the primary Ascorer search algorithm before they are shown to users. They can modify a document’s retrieval score or its ranking, resembling WordPress filters and actions.
Moreover, Twiddlers can enforce category constraints to ensure diversity, such as limiting a SERP to only three blog posts, which helps clarify when certain rankings are unachievable due to page format.
When Google says an update like Panda isn’t part of the core algorithm, it likely started as a Twiddler that adjusted rankings before being integrated into the main system. This is similar to the distinction between server-side and client-side rendering.
1. The Importance of Authorship
Authorship is now confirmed as one of the vital factors in Google’s search algorithm. Despite ongoing skepticism about the E-A-T (Expertise, Authoritativeness, Trustworthiness) framework due to the difficulty of quantifying these qualities, recent insights shed new light on Google’s approach.
The leaked documents reveal that Google tracks authors linked to content. Algorithms gauge if a named entity on a page is also the actual author using advanced techniques like vector embeddings and entity mapping.
2. Algorithmic Demotions
The following demotions affect a website’s ranking based on specific negative factors:
- Anchor Mismatch: Links are demoted if the anchor text doesn’t match the content of the target site, emphasizing the need for relevance in both link creation and target content.
- SERP Demotion: Pages may be demoted based on user behavior in the search results, such as low click-through rates, indicating user dissatisfaction.
- Nav Demotion: Pages with poor navigation or subpar user experience can be demoted, highlighting the importance of good site structure and usability.
- Exact Match Domains Demotion: Since 2012, domains that exactly match search queries have been given less ranking value, so having an exact match domain is no longer a strong advantage.
- Product Review Demotion: Likely linked to recent updates, poor-quality product reviews can lead to demotion.
- Location Demotions: Global and super-global pages may be demoted in favor of more locally relevant content.
- Porn Content: Unsurprisingly, pages containing explicit content are synonymous with demotion.
3. Links Still Matter
Despite some claims suggesting links are no longer as valuable, there’s no evidence in leaked docs to support this. While the actual scoring might happen within the algorithm itself, Google aims to understand the link graph by meticulously extracting and engineering features related to links.
4. Link Spam Detection
Google has developed metrics to detect spikes in spammy anchor text, using a feature called phraseAnchorSpamDays. This allows Google to measure the velocity of spam links, helping to identify spamming sites and neutralize negative SEO attacks by comparing link trends to a baseline and disregarding suspicious links.
5. Link Analysis Based on Recent Changes
Google only considers the last 20 changes to a URL when analyzing links, despite keeping all historical versions. Therefore, frequent updates are necessary to reset link equity, as older changes become irrelevant in Google’s evaluation.
6. Link Value and Indexing Tier
Google’s indexing tiers impact link value, with higher-tier pages—stored in fast-access memory—offering more valuable links. Fresh, frequently updated content ranks higher, making links from such pages more beneficial for SEO.
7. Homepage PageRank’s Influence on New Pages
Google uses the PageRank of a website’s homepage as a stand-in metric for new pages until they develop their own PageRank. This initial ranking, along with siteAuthority, helps assess new pages before they establish their individual metrics.
8. Font Size and Link Importance
Google tracks the average font size of terms and anchor text in documents, confirming that using larger or emphasized text can influence rankings. For SEO professionals, this means that highlighting important text and links through font size can still positively impact search visibility.
9. Homepage Trust
Google evaluates the trustworthiness of a link based on the credibility of its homepage, so SEO professionals should prioritize quality and relevance over the sheer number of links.
10. Originality Over Length for Short Content
Keep in mind that Google’s algorithm analyzes short content for originality, not just length, which is why even brief content can rank well if it’s unique, while also penalizing keyword stuffing.
11. Prioritize Important Content Early
Google’s algorithm limits the number of tokens it considers per document, so authors should place their most important content at the beginning.
12. Internal Links and Penguin Algorithm
The Penguin algorithm now appears to disregard some internal links, as indicated by the droppedLocalAnchorCount, meaning not all internal links on the same site are counted in the ranking process.
13. The Alignment Between Page Titles and Search Queries
Google continues prioritizing how well page titles match search queries, emphasizing the importance of placing target keywords at the forefront.
14. Dates Matter
Fresh content is highly valuable to Google, explaining why algorithms focus on accurate dates. It assesses three key date attributes—bylineDate (explicitly set), syntacticDate (extracted from URL or title), and semanticDate (derived from page content)—to ensure consistency across structured data, page titles, and XML sitemaps.
15. No Character Counting
Character count metrics for page titles and snippets aren’t important to Google’s algorithm. While lengthy page titles may not optimize click-through rates, they can still positively influence rankings.
16. Video-Focused Sites
Google treats sites with over 50 percent of pages containing videos differently, potentially impacting their search rankings.
17. Domain Registration Storage
Google stores domain registration details at a document level, which affects search rankings for new and transferred domains under updated spam policies.
18. YMYL Classification and Scoring
Google uses classifiers to score content under YMYL (Your Money Your Life) categories like Health and News and predicts if new or unusual queries fall under YMYL, with scoring based on chunk-level embeddings.
19. Gold Standard Documents
The leaked Google SEO documentation mentions Gold Standard Documents labeled by humans, which may impact quality evaluation despite claims that quality ratings don’t directly influence rankings.
20. Site Embeddings and Page Relevance
The algorithm uses site embeddings to gauge whether a page matches the website’s overarching theme. This evaluation, measured through metrics like siteFocusScore and site radius derived from site2vec vectors, helps determine content relevance and search result precision.
21. Google’s Treatment of Small Websites
Google may have a flag for identifying small personal sites, which could have a say in their visibility in search results, potentially affecting smaller businesses disproportionately.
What do the ranking factors revealed in the Google algorithm leak mean for SEO?
Google Search Document Leak and the Future of SEO
While Google’s algorithms remain largely nebulous, the recent leak of Google’s search documents offers rare insights. However, approach these findings cautiously, as some details may no longer be relevant or could change soon.
Instead of relying solely on these documents, prioritize creating high-quality content that matches your audience’s needs. This is an evergreen practice. Google emphasizes user experience and engagement metrics, so focus your efforts on delivering content that resonates and encourages interaction.
Continuously diversify your SEO strategies and test their effectiveness. Moreover, teaming up with experienced professionals can provide invaluable guidance in navigating the ranking factors revealed in the Google search algorithm leak.
Explore SEO services to maximize the impact of these insights on your website’s visibility and performance in search results.




